

I am a 1st year CS PhD student at Duke University, advised by Prof. Anru Zhang.
I study the science of advanced AI models.
My current research centers on understanding how and why advanced AI models—such as large language models and diffusion models—work, and on leveraging this understanding to make them more accurate, efficient, and robust. I am obsessed with understanding intelligence from first principles.
I am always open to discussions and collaborations. Feel free to reach out.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Duke UniversityPh.D. in Computer ScienceAug. 2025 – Present
Duke UniversityPh.D. in Computer ScienceAug. 2025 – Present -
 University of PennsylvaniaM.S.E. in Scientific ComputingAug. 2023 - May. 2025
University of PennsylvaniaM.S.E. in Scientific ComputingAug. 2023 - May. 2025 -
 Wuhan UniversityB.E. in Engineering MechanicsSep. 2019 - Jul. 2023
Wuhan UniversityB.E. in Engineering MechanicsSep. 2019 - Jul. 2023
Experience
-
 ByteDance, San Jose, CAResearch Scientist Intern (ML System)Jun. 2026 - Aug. 2026
ByteDance, San Jose, CAResearch Scientist Intern (ML System)Jun. 2026 - Aug. 2026
News
Selected Publications (view all )
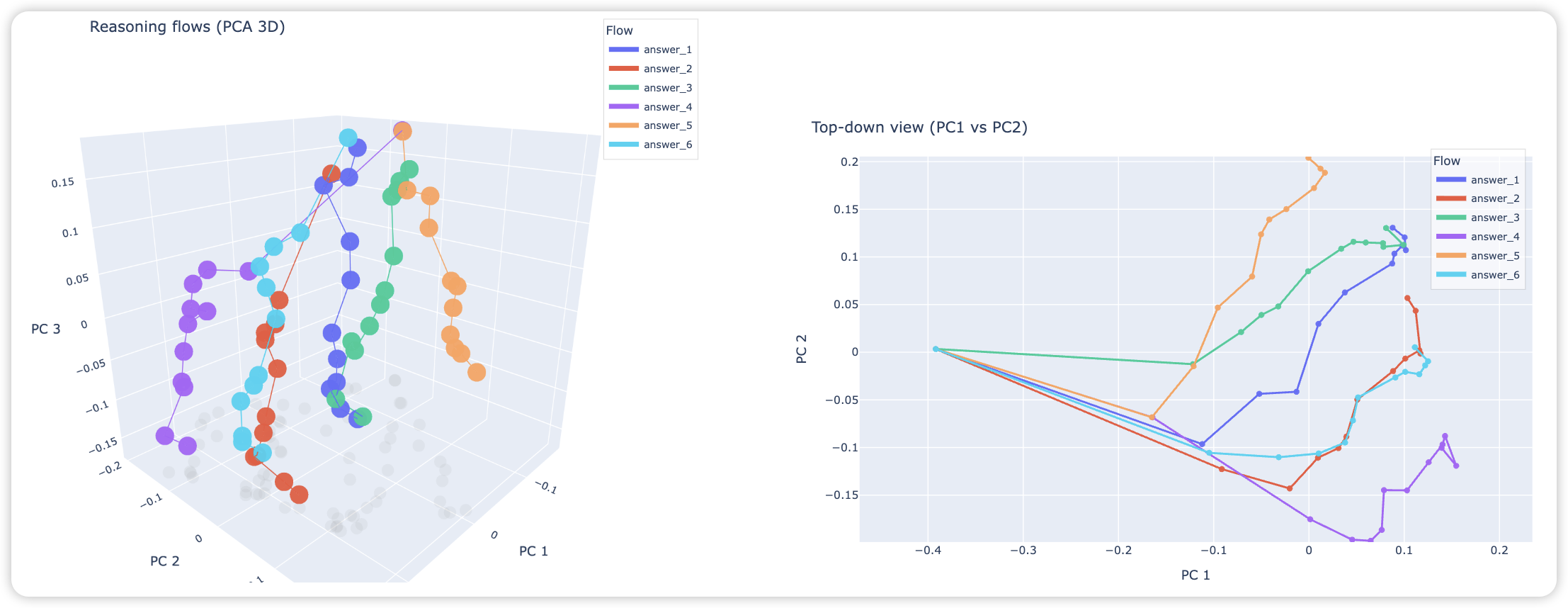
The Geometry of Reasoning: Flowing Logics in Representation Space
Yufa Zhou*, Yixiao Wang*, Xunjian Yin*, Shuyan Zhou, Anru R. Zhang(* equal contribution)
ICLR 2026
We study how LLMs “think” through their embeddings by introducing a geometric framework of reasoning flows, where reasoning emerges as smooth trajectories in representation space whose velocity and curvature are governed by logical structure rather than surface semantics, validated through cross-topic and cross-language experiments, opening a new lens for interpretability.
The Geometry of Reasoning: Flowing Logics in Representation Space
Yufa Zhou*, Yixiao Wang*, Xunjian Yin*, Shuyan Zhou, Anru R. Zhang(* equal contribution)
ICLR 2026
We study how LLMs “think” through their embeddings by introducing a geometric framework of reasoning flows, where reasoning emerges as smooth trajectories in representation space whose velocity and curvature are governed by logical structure rather than surface semantics, validated through cross-topic and cross-language experiments, opening a new lens for interpretability.
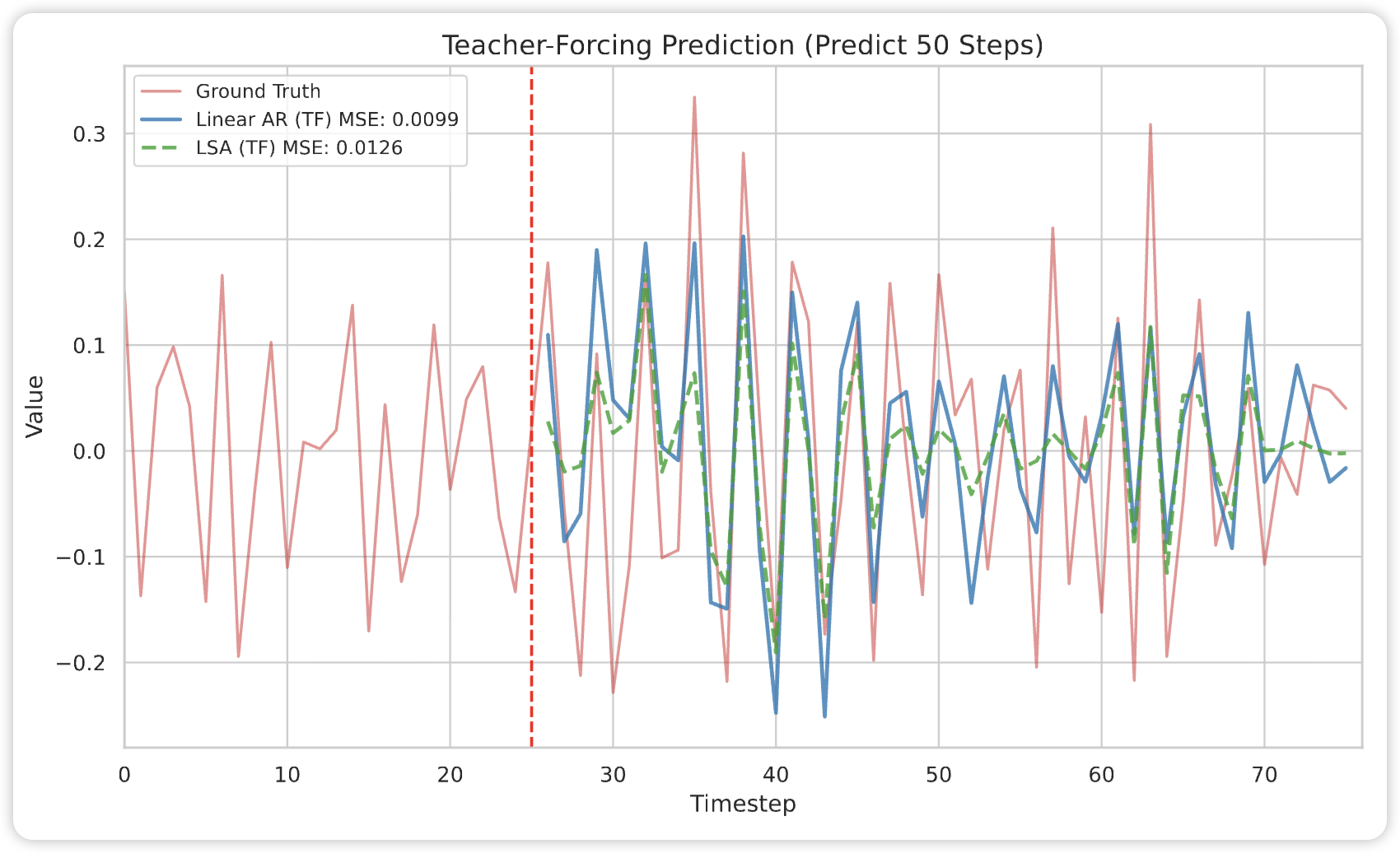
Why Do Transformers Fail to Forecast Time Series In-Context?
Yufa Zhou*, Yixiao Wang*, Surbhi Goel, Anru R. Zhang(* equal contribution)
NeurIPS 2025 Workshop: What Can('t) Transformers Do? Oral (3/68 ≈ 4.4%)
We analyze why Transformers fail in time-series forecasting through in-context learning theory, proving that, under AR($p$) data, linear self-attention cannot outperform classical linear predictors and suffers a strict $O(1/n)$ excess-risk gap, while chain-of-thought inference compounds errors exponentially—revealing fundamental representational limits of attention and offering principled insights.
Why Do Transformers Fail to Forecast Time Series In-Context?
Yufa Zhou*, Yixiao Wang*, Surbhi Goel, Anru R. Zhang(* equal contribution)
NeurIPS 2025 Workshop: What Can('t) Transformers Do? Oral (3/68 ≈ 4.4%)
We analyze why Transformers fail in time-series forecasting through in-context learning theory, proving that, under AR($p$) data, linear self-attention cannot outperform classical linear predictors and suffers a strict $O(1/n)$ excess-risk gap, while chain-of-thought inference compounds errors exponentially—revealing fundamental representational limits of attention and offering principled insights.
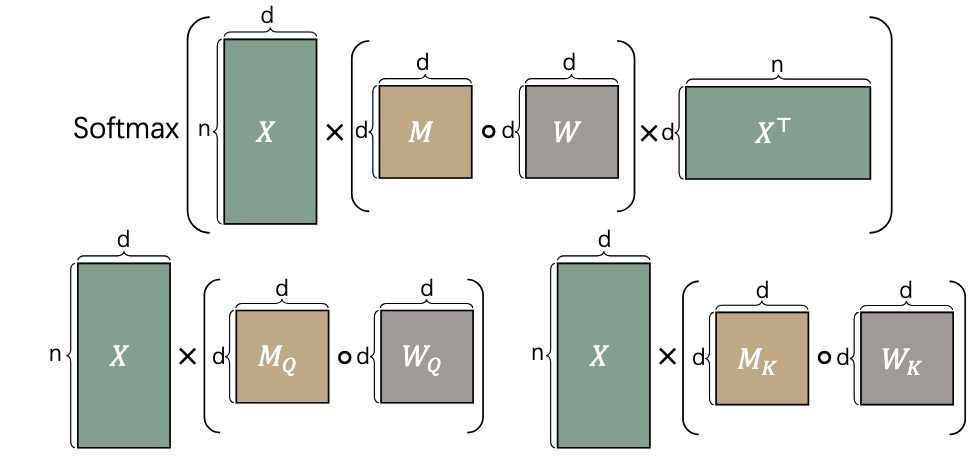
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Yingyu Liang*, Jiangxuan Long*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
ICLR 2025
We introduce a novel LLM weight pruning method that directly optimizes for approximating the non-linear attention matrix—with theoretical convergence guarantees—effectively reducing computational costs while maintaining model performance.
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Yingyu Liang*, Jiangxuan Long*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
ICLR 2025
We introduce a novel LLM weight pruning method that directly optimizes for approximating the non-linear attention matrix—with theoretical convergence guarantees—effectively reducing computational costs while maintaining model performance.
All publications
Mentees
-
Yixiao Wang — MS in Statistical Science @ Duke
Teaching
-
COMPSCI 590.04: Principles of Deep Learning (Spring 2026, Duke) — Instructor: Prof. Rong Ge
Academic Services
-
Conference Reviewer: ICLR (2025, 2026), NeurIPS 2026, ICML 2026, AAAI 2026.