2026
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Shaobo Wang, Yantai Yang, Guo Chen, Peiru Li, Kaixin Li, Yufa Zhou, Zhaorun Chen, Linfeng Zhang
ICLR 2026
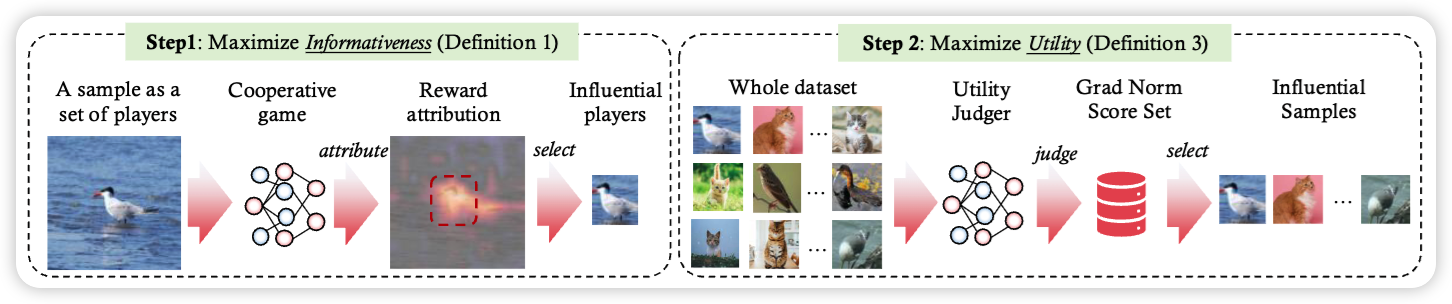
We propose InfoUtil, a principled dataset distillation framework that formalizes informativeness and utility, leveraging Shapley value attribution and gradient-norm-based selection to synthesize compact yet highly effective datasets, achieving consistent SOTA performance and efficiency across architectures and benchmarks.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Shaobo Wang, Yantai Yang, Guo Chen, Peiru Li, Kaixin Li, Yufa Zhou, Zhaorun Chen, Linfeng Zhang
ICLR 2026
We propose InfoUtil, a principled dataset distillation framework that formalizes informativeness and utility, leveraging Shapley value attribution and gradient-norm-based selection to synthesize compact yet highly effective datasets, achieving consistent SOTA performance and efficiency across architectures and benchmarks.
FastCar: Cache Attentive Replay for Fast Auto-Regressive Video Generation on the Edge
Xuan Shen, Weize Ma, Yufa Zhou, Enhao Tang, Yanyue Xie, Zhengang Li, Yifan Gong, Quanyi Wang, Henghui Ding, Yiwei Wang, Yanzhi Wang, Pu Zhao, Jun Lin, Jiuxiang Gu
ICLR 2026
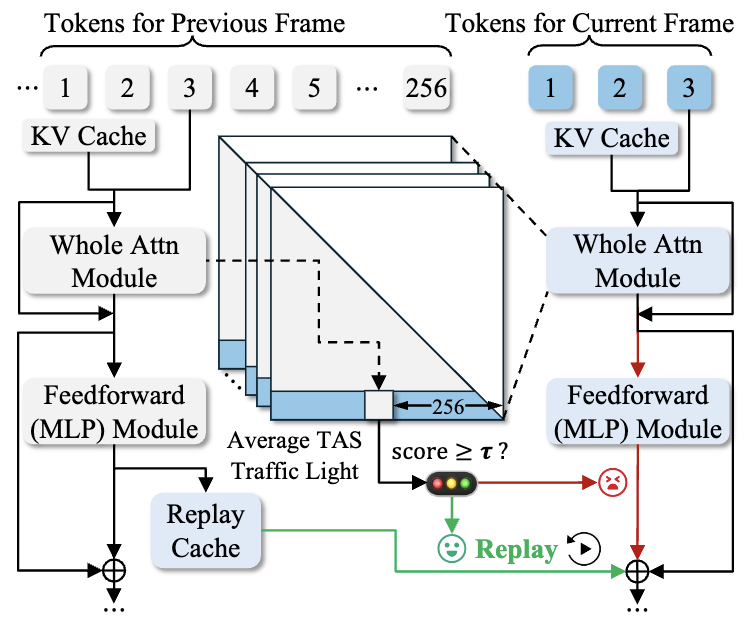
We propose FastCar, a unified framework that accelerates auto-regressive video generation by exploiting temporal redundancy through a Temporal Attention Score for selective computation reuse, integrating with sparse attention and dynamic scheduling to enable real-time, high-resolution synthesis with over 2.1× speedup and minimal quality loss.
FastCar: Cache Attentive Replay for Fast Auto-Regressive Video Generation on the Edge
Xuan Shen, Weize Ma, Yufa Zhou, Enhao Tang, Yanyue Xie, Zhengang Li, Yifan Gong, Quanyi Wang, Henghui Ding, Yiwei Wang, Yanzhi Wang, Pu Zhao, Jun Lin, Jiuxiang Gu
ICLR 2026
We propose FastCar, a unified framework that accelerates auto-regressive video generation by exploiting temporal redundancy through a Temporal Attention Score for selective computation reuse, integrating with sparse attention and dynamic scheduling to enable real-time, high-resolution synthesis with over 2.1× speedup and minimal quality loss.
The Geometry of Reasoning: Flowing Logics in Representation Space
Yufa Zhou*, Yixiao Wang*, Xunjian Yin*, Shuyan Zhou, Anru R. Zhang(* equal contribution)
ICLR 2026
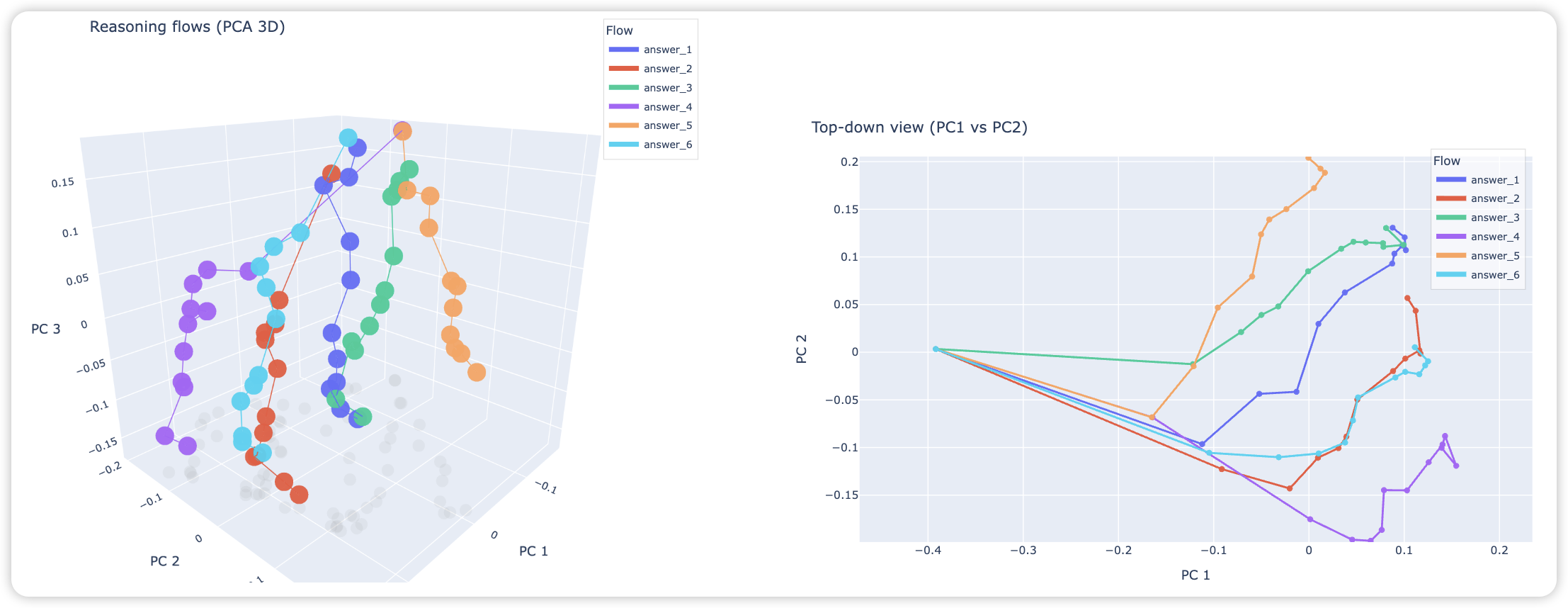
We study how LLMs “think” through their embeddings by introducing a geometric framework of reasoning flows, where reasoning emerges as smooth trajectories in representation space whose velocity and curvature are governed by logical structure rather than surface semantics, validated through cross-topic and cross-language experiments, opening a new lens for interpretability.
The Geometry of Reasoning: Flowing Logics in Representation Space
Yufa Zhou*, Yixiao Wang*, Xunjian Yin*, Shuyan Zhou, Anru R. Zhang(* equal contribution)
ICLR 2026
We study how LLMs “think” through their embeddings by introducing a geometric framework of reasoning flows, where reasoning emerges as smooth trajectories in representation space whose velocity and curvature are governed by logical structure rather than surface semantics, validated through cross-topic and cross-language experiments, opening a new lens for interpretability.
2025

Automating Structural Engineering Workflows with Large Language Model Agents
Haoran Liang*, Yufa Zhou*, Mohammad Talebi-Kalaleh, Qipei Mei(* equal contribution)
arXiv 2025
We present MASSE, the first multi-agent system that automates structural engineering workflows by integrating reasoning, planning, and tool use to perform complex design and verification tasks—achieving training-free automation that cuts expert workload from hours to minutes and demonstrates tangible real-world impact.
Automating Structural Engineering Workflows with Large Language Model Agents
Haoran Liang*, Yufa Zhou*, Mohammad Talebi-Kalaleh, Qipei Mei(* equal contribution)
arXiv 2025
We present MASSE, the first multi-agent system that automates structural engineering workflows by integrating reasoning, planning, and tool use to perform complex design and verification tasks—achieving training-free automation that cuts expert workload from hours to minutes and demonstrates tangible real-world impact.
Why Do Transformers Fail to Forecast Time Series In-Context?
Yufa Zhou*, Yixiao Wang*, Surbhi Goel, Anru R. Zhang(* equal contribution)
NeurIPS 2025 Workshop: What Can('t) Transformers Do? Oral (3/68 ≈ 4.4%)
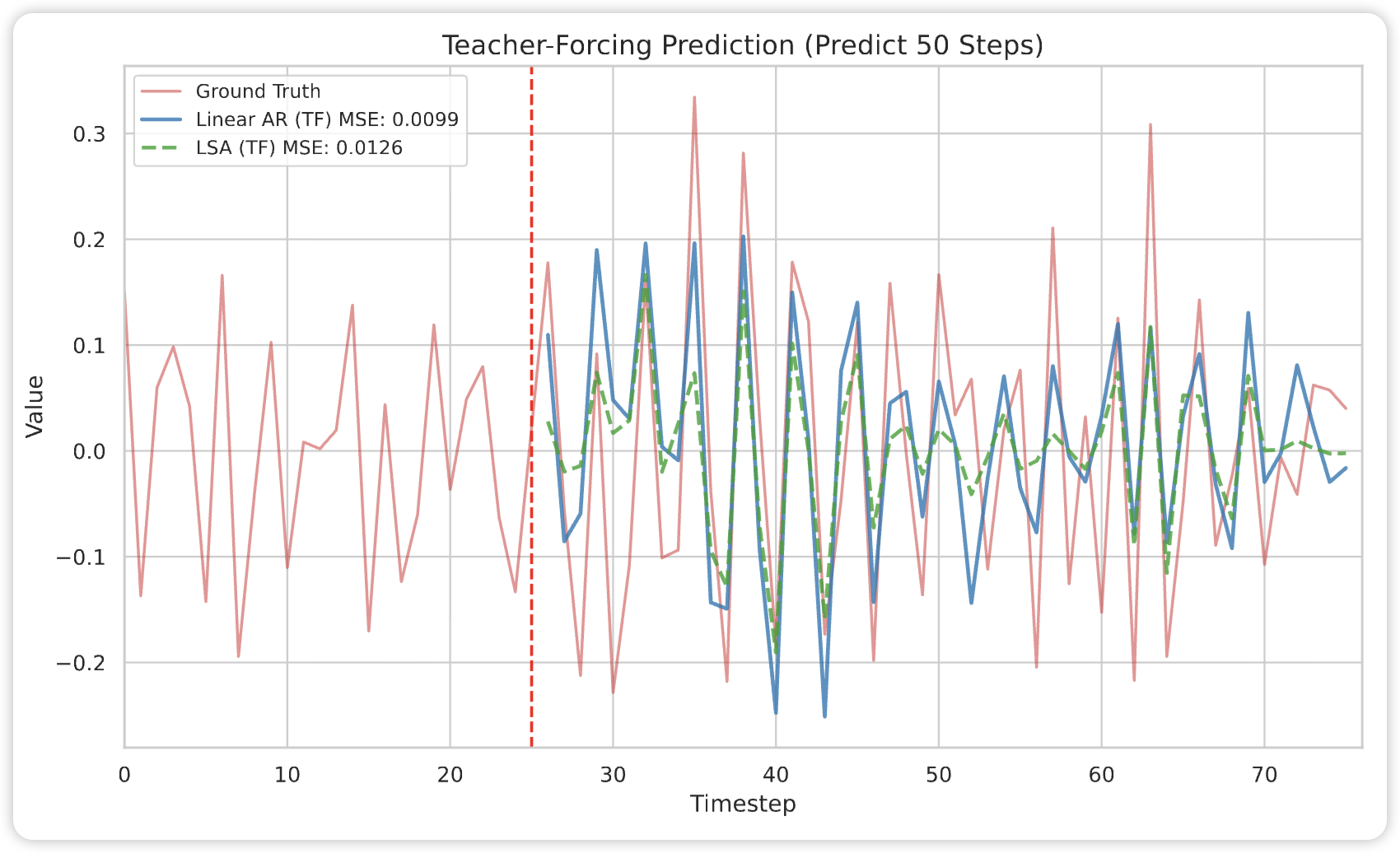
We analyze why Transformers fail in time-series forecasting through in-context learning theory, proving that, under AR($p$) data, linear self-attention cannot outperform classical linear predictors and suffers a strict $O(1/n)$ excess-risk gap, while chain-of-thought inference compounds errors exponentially—revealing fundamental representational limits of attention and offering principled insights.
Why Do Transformers Fail to Forecast Time Series In-Context?
Yufa Zhou*, Yixiao Wang*, Surbhi Goel, Anru R. Zhang(* equal contribution)
NeurIPS 2025 Workshop: What Can('t) Transformers Do? Oral (3/68 ≈ 4.4%)
We analyze why Transformers fail in time-series forecasting through in-context learning theory, proving that, under AR($p$) data, linear self-attention cannot outperform classical linear predictors and suffers a strict $O(1/n)$ excess-risk gap, while chain-of-thought inference compounds errors exponentially—revealing fundamental representational limits of attention and offering principled insights.
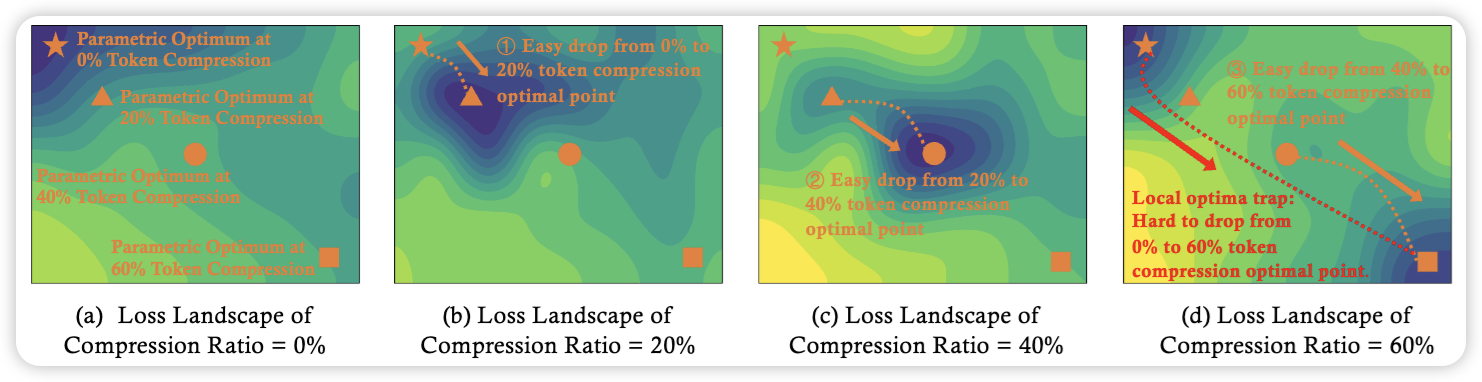
Efficient Multi-modal Large Language Models via Progressive Consistency Distillation
Zichen Wen, Shaobo Wang, Yufa Zhou, Junyuan Zhang, Qintong Zhang, Yifeng Gao, Zhaorun Chen, Bin Wang, Weijia Li, Conghui He, Linfeng Zhang
NeurIPS 2025
We propose EPIC, a progressive consistency distillation framework that mitigates the training difficulty of token compression in multi-modal LLMs by enforcing token- and layer-level consistency, achieving superior efficiency, robustness, and generalization across benchmarks.
Efficient Multi-modal Large Language Models via Progressive Consistency Distillation
Zichen Wen, Shaobo Wang, Yufa Zhou, Junyuan Zhang, Qintong Zhang, Yifeng Gao, Zhaorun Chen, Bin Wang, Weijia Li, Conghui He, Linfeng Zhang
NeurIPS 2025
We propose EPIC, a progressive consistency distillation framework that mitigates the training difficulty of token compression in multi-modal LLMs by enforcing token- and layer-level consistency, achieving superior efficiency, robustness, and generalization across benchmarks.
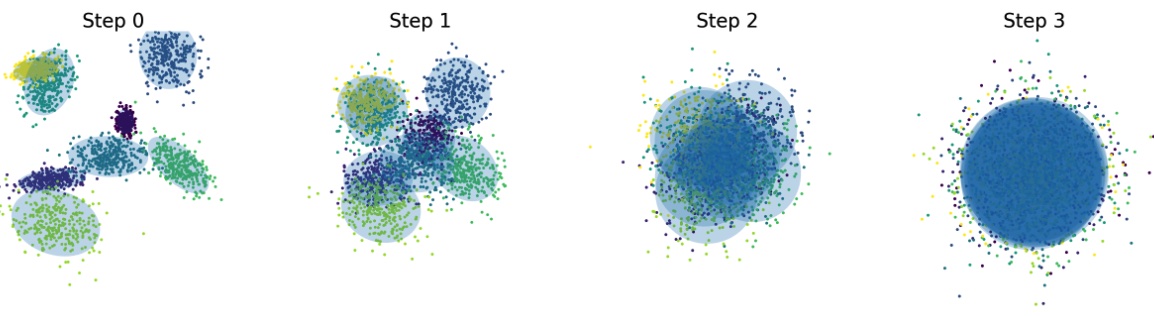
Unraveling the Smoothness Properties of Diffusion Models: A Gaussian Mixture Perspective
Yingyu Liang*, Zhizhou Sha*, Zhenmei Shi*, Zhao Song*, Mingda Wan*, Yufa Zhou*(α–β alphabetical order)
ICCV 2025
We provide a theoretical analysis showing that for diffusion models with Gaussian mixture data, the diffusion process preserves the mixture structure; we derive tight, component-independent bounds on Lipschitz constants and second moments, and establish error guarantees for diffusion solvers—offering deeper insights into the diffusion dynamics under common data distributions.
Unraveling the Smoothness Properties of Diffusion Models: A Gaussian Mixture Perspective
Yingyu Liang*, Zhizhou Sha*, Zhenmei Shi*, Zhao Song*, Mingda Wan*, Yufa Zhou*(α–β alphabetical order)
ICCV 2025
We provide a theoretical analysis showing that for diffusion models with Gaussian mixture data, the diffusion process preserves the mixture structure; we derive tight, component-independent bounds on Lipschitz constants and second moments, and establish error guarantees for diffusion solvers—offering deeper insights into the diffusion dynamics under common data distributions.
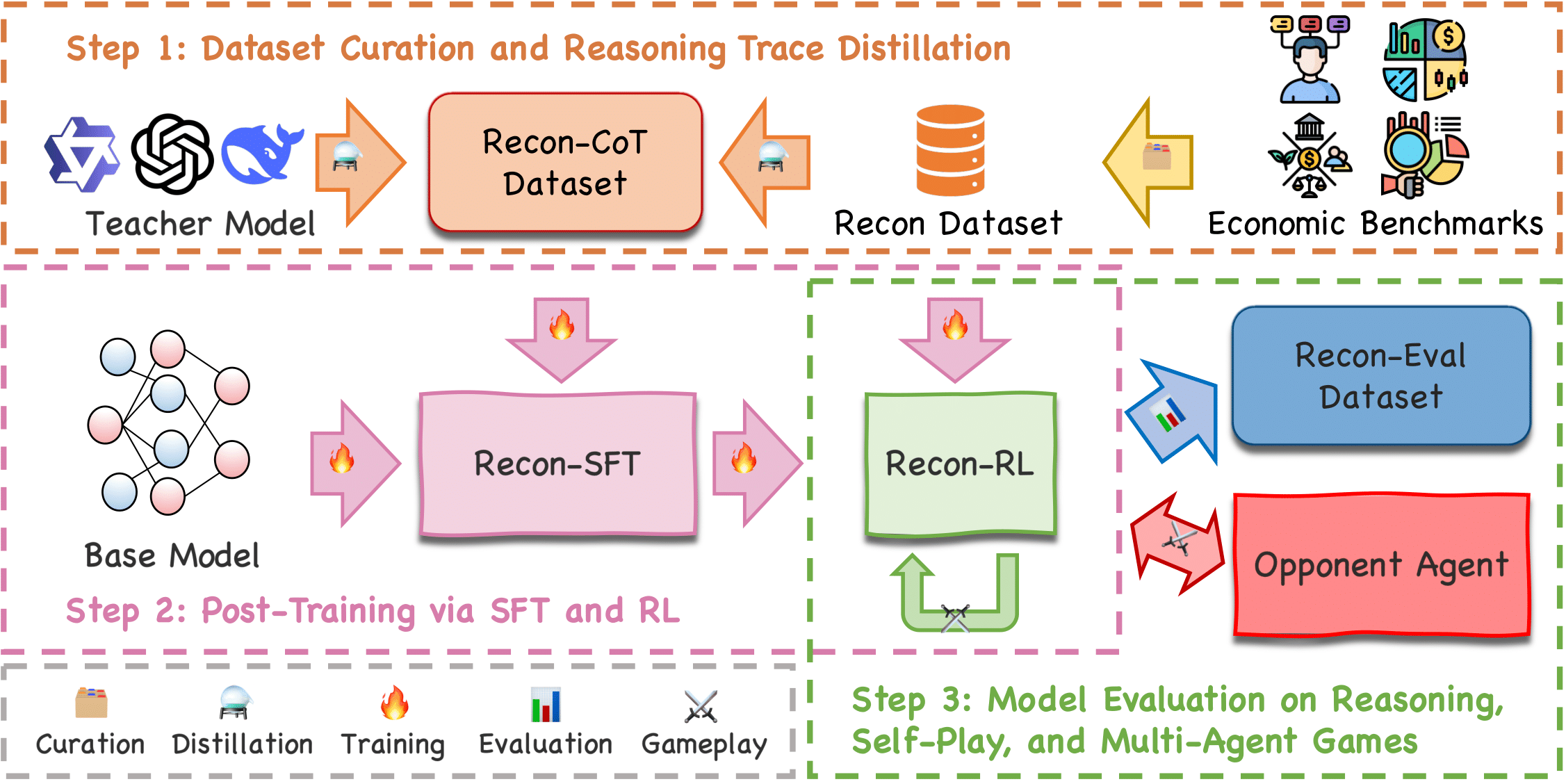
Reasoning Like an Economist: Post-Training on Economic Problems Induces Strategic Generalization in LLMs
Yufa Zhou*, Shaobo Wang*, Xingyu Dong*, Xiangqi Jin, Yifang Chen, Yue Min, Kexin Yang, Xingzhang Ren, Dayiheng Liu, Linfeng Zhang(* equal contribution)
arXiv 2025
We investigate whether post-training techniques such as SFT and RLVR can generalize to multi-agent systems, and introduce Recon—a 7B model trained on a curated dataset of economic reasoning problems—which achieves strong benchmark performance and exhibits emergent strategic generalization in multi-agent games.
Reasoning Like an Economist: Post-Training on Economic Problems Induces Strategic Generalization in LLMs
Yufa Zhou*, Shaobo Wang*, Xingyu Dong*, Xiangqi Jin, Yifang Chen, Yue Min, Kexin Yang, Xingzhang Ren, Dayiheng Liu, Linfeng Zhang(* equal contribution)
arXiv 2025
We investigate whether post-training techniques such as SFT and RLVR can generalize to multi-agent systems, and introduce Recon—a 7B model trained on a curated dataset of economic reasoning problems—which achieves strong benchmark performance and exhibits emergent strategic generalization in multi-agent games.
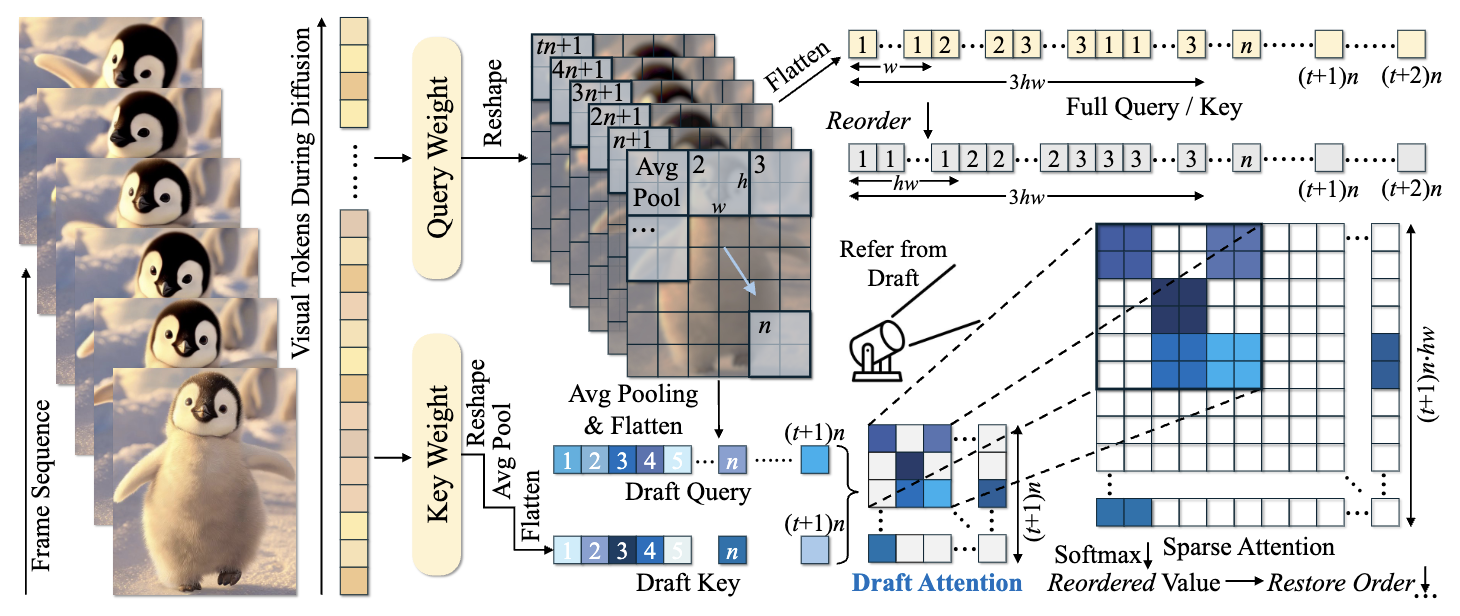
DraftAttention: Fast Video Diffusion via Low-Resolution Attention Guidance
Xuan Shen*, Chenxia Han*, Yufa Zhou*, Yanyue Xie, Yifan Gong, Quanyi Wang, Yiwei Wang, Yanzhi Wang, Pu Zhao, Jiuxiang Gu(* equal contribution)
arXiv 2025
We propose DraftAttention, a method that accelerates video diffusion transformers by leveraging low-resolution pooled attention maps to enable dynamic sparse attention and hardware-efficient execution, achieving up to 1.75× speedup with minimal quality loss.
DraftAttention: Fast Video Diffusion via Low-Resolution Attention Guidance
Xuan Shen*, Chenxia Han*, Yufa Zhou*, Yanyue Xie, Yifan Gong, Quanyi Wang, Yiwei Wang, Yanzhi Wang, Pu Zhao, Jiuxiang Gu(* equal contribution)
arXiv 2025
We propose DraftAttention, a method that accelerates video diffusion transformers by leveraging low-resolution pooled attention maps to enable dynamic sparse attention and hardware-efficient execution, achieving up to 1.75× speedup with minimal quality loss.
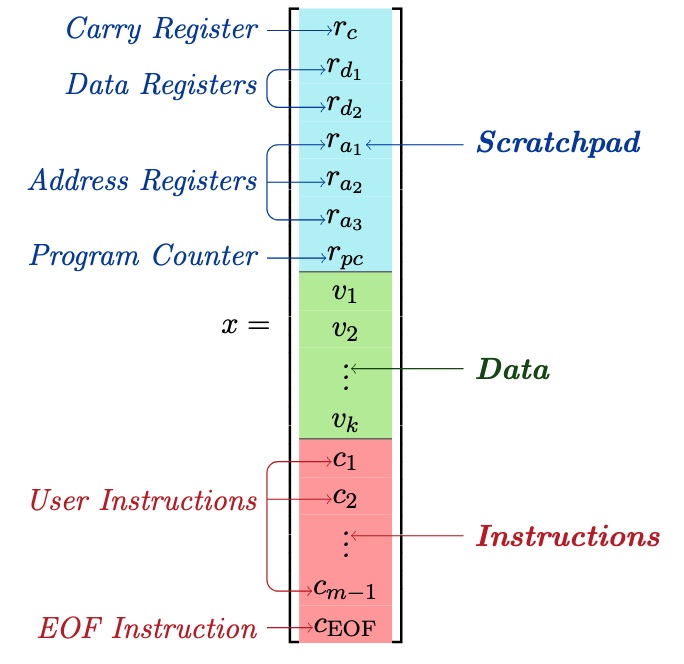
Looped relu mlps may be all you need as practical programmable computers
Yingyu Liang*, Zhizhou Sha*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
AISTATS 2025
We demonstrate that a looped 23-layer ReLU-MLP can function as a universal programmable computer—revealing that simple neural network modules possess greater expressive power than previously thought and can perform complex tasks without relying on advanced architectures like Transformers.
Looped relu mlps may be all you need as practical programmable computers
Yingyu Liang*, Zhizhou Sha*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
AISTATS 2025
We demonstrate that a looped 23-layer ReLU-MLP can function as a universal programmable computer—revealing that simple neural network modules possess greater expressive power than previously thought and can perform complex tasks without relying on advanced architectures like Transformers.
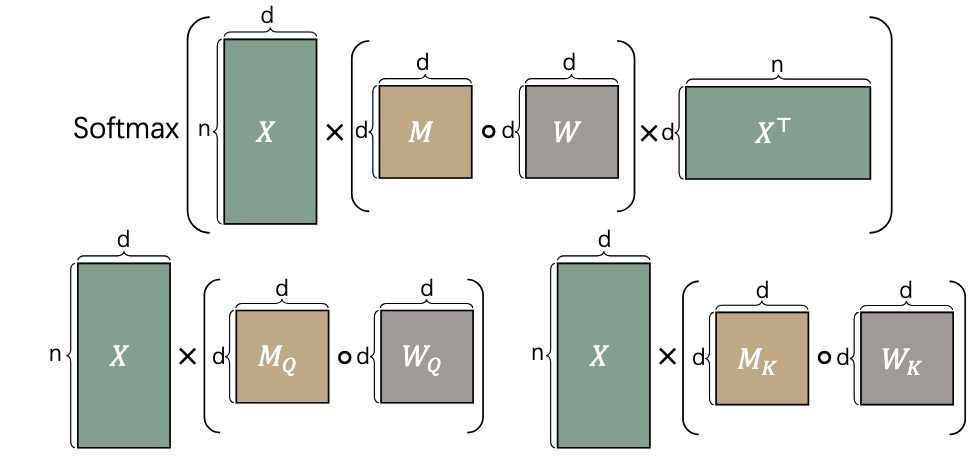
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Yingyu Liang*, Jiangxuan Long*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
ICLR 2025
We introduce a novel LLM weight pruning method that directly optimizes for approximating the non-linear attention matrix—with theoretical convergence guarantees—effectively reducing computational costs while maintaining model performance.
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Yingyu Liang*, Jiangxuan Long*, Zhenmei Shi*, Zhao Song*, Yufa Zhou*(α–β alphabetical order)
ICLR 2025
We introduce a novel LLM weight pruning method that directly optimizes for approximating the non-linear attention matrix—with theoretical convergence guarantees—effectively reducing computational costs while maintaining model performance.
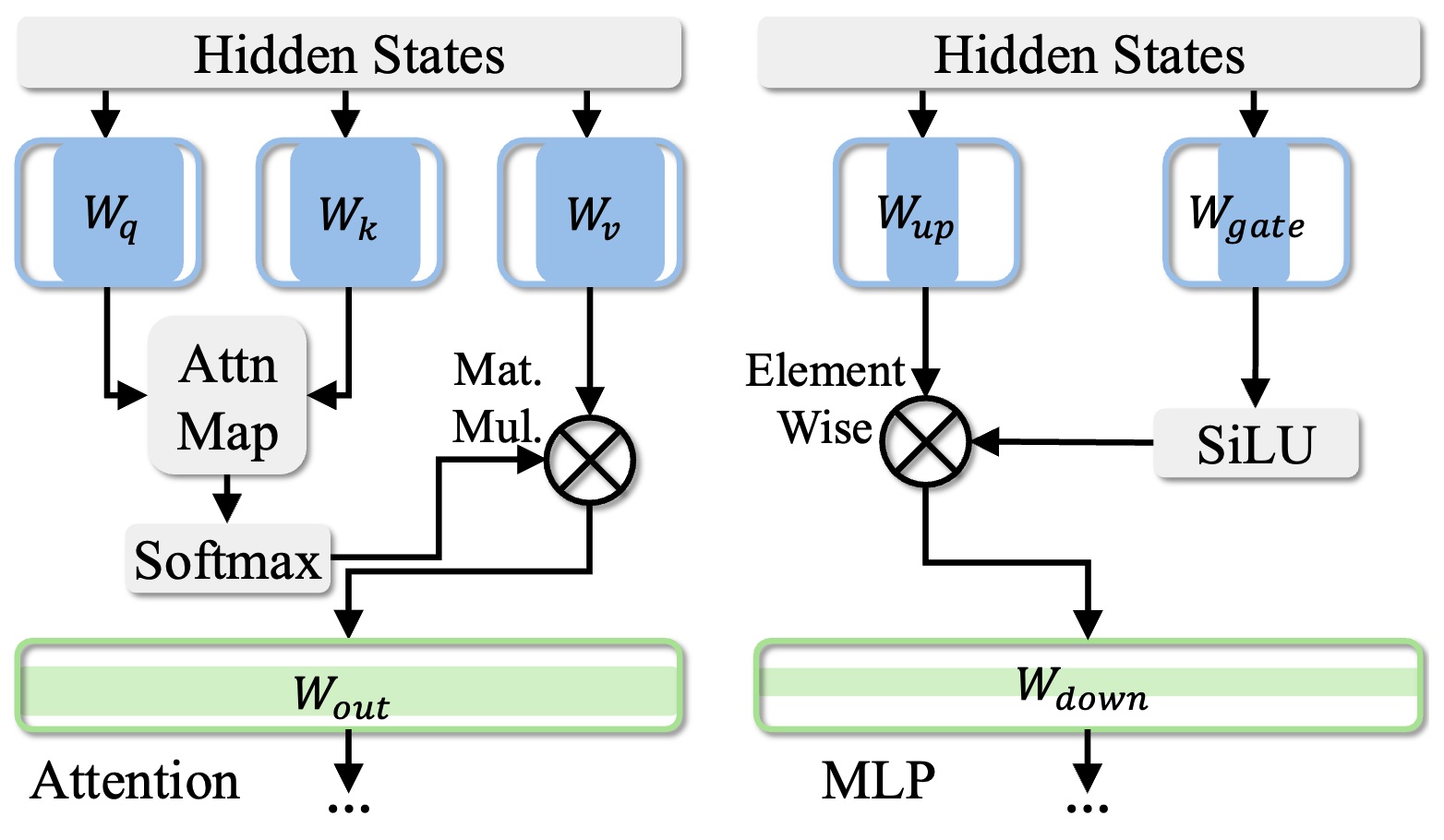
Numerical Pruning for Efficient Autoregressive Models
Xuan Shen, Zhao Song, Yufa Zhou, Bo Chen, Jing Liu, Ruiyi Zhang, Ryan A. Rossi, Hao Tan, Tong Yu, Xiang Chen, Yufan Zhou, Tong Sun, Pu Zhao, Yanzhi Wang, Jiuxiang Gu
AAAI 2025
We present a training-free structural pruning method using Newton’s method and compensation algorithms to efficiently compress decoder-only transformer models, achieving state-of-the-art performance with reduced memory usage and faster generation on GPUs.
Numerical Pruning for Efficient Autoregressive Models
Xuan Shen, Zhao Song, Yufa Zhou, Bo Chen, Jing Liu, Ruiyi Zhang, Ryan A. Rossi, Hao Tan, Tong Yu, Xiang Chen, Yufan Zhou, Tong Sun, Pu Zhao, Yanzhi Wang, Jiuxiang Gu
AAAI 2025
We present a training-free structural pruning method using Newton’s method and compensation algorithms to efficiently compress decoder-only transformer models, achieving state-of-the-art performance with reduced memory usage and faster generation on GPUs.
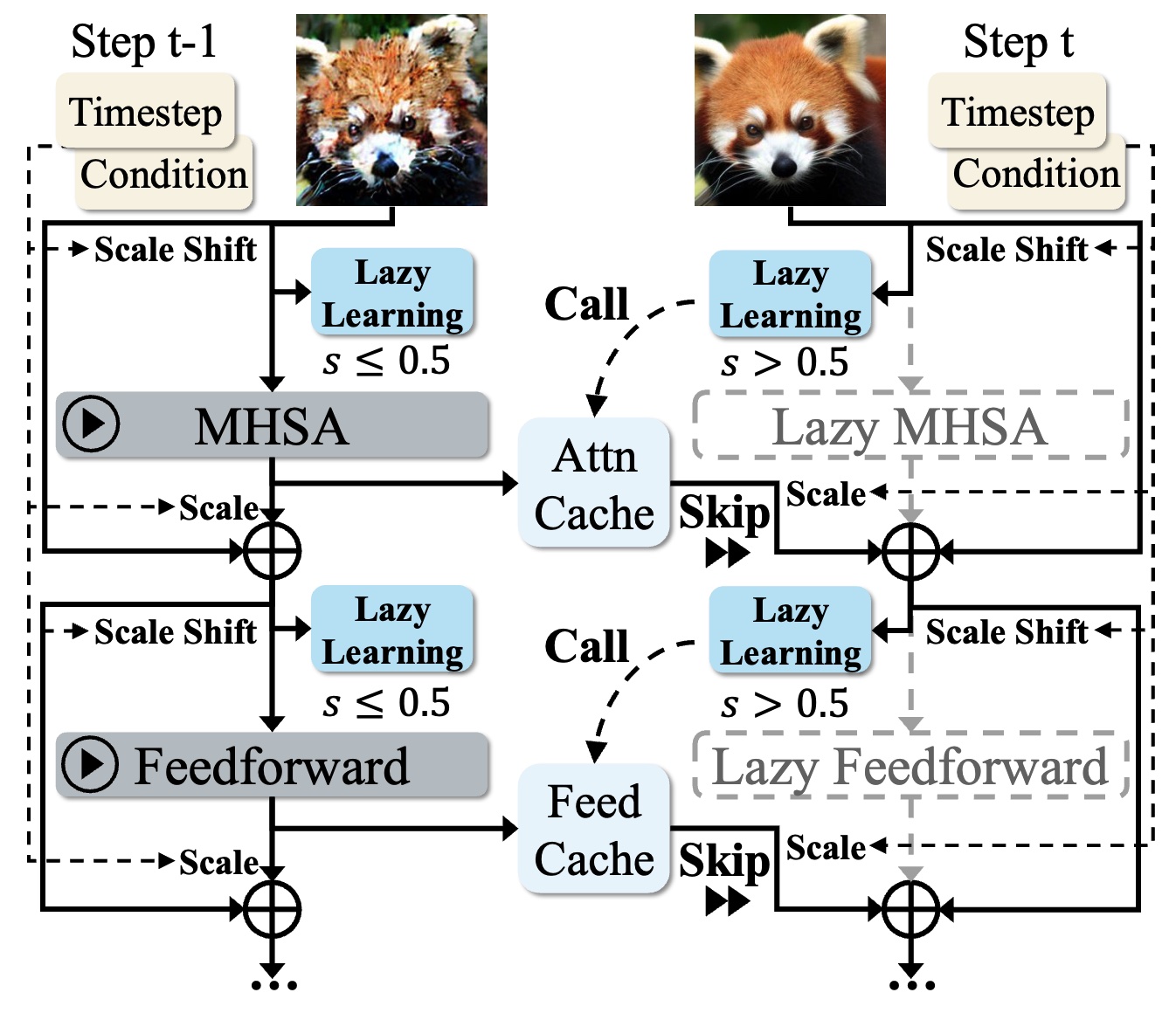
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Xuan Shen, Zhao Song, Yufa Zhou, Bo Chen, Yanyu Li, Yifan Gong, Kai Zhang, Hao Tan, Jason Kuen, Henghui Ding, Zhihao Shu, Wei Niu, Pu Zhao, Yanzhi Wang, Jiuxiang Gu
AAAI 2025
We present LazyDiT, a framework that accelerates Diffusion Transformers by reusing computations from previous steps and dynamically skipping redundancies, achieving superior performance over existing methods like DDIM across multiple models and devices.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Xuan Shen, Zhao Song, Yufa Zhou, Bo Chen, Yanyu Li, Yifan Gong, Kai Zhang, Hao Tan, Jason Kuen, Henghui Ding, Zhihao Shu, Wei Niu, Pu Zhao, Yanzhi Wang, Jiuxiang Gu
AAAI 2025
We present LazyDiT, a framework that accelerates Diffusion Transformers by reusing computations from previous steps and dynamically skipping redundancies, achieving superior performance over existing methods like DDIM across multiple models and devices.